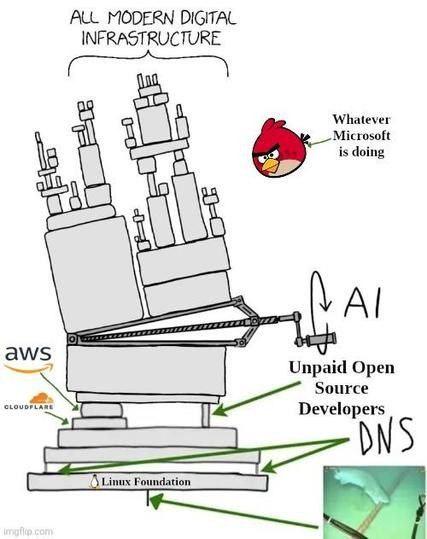
AI
AI
 AWS
AWS
 Agile
Agile
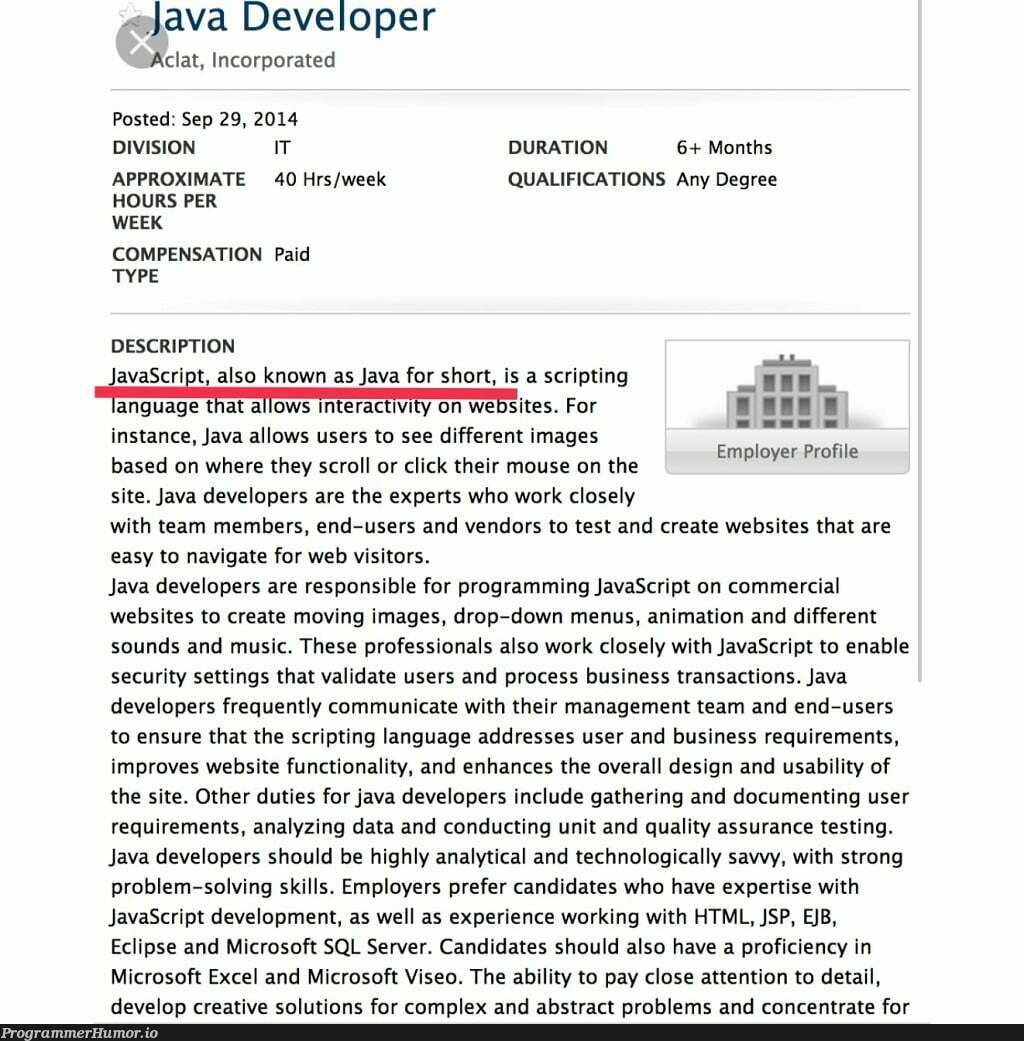
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Bash
Bash
 C++
C++
 Csharp
Csharp
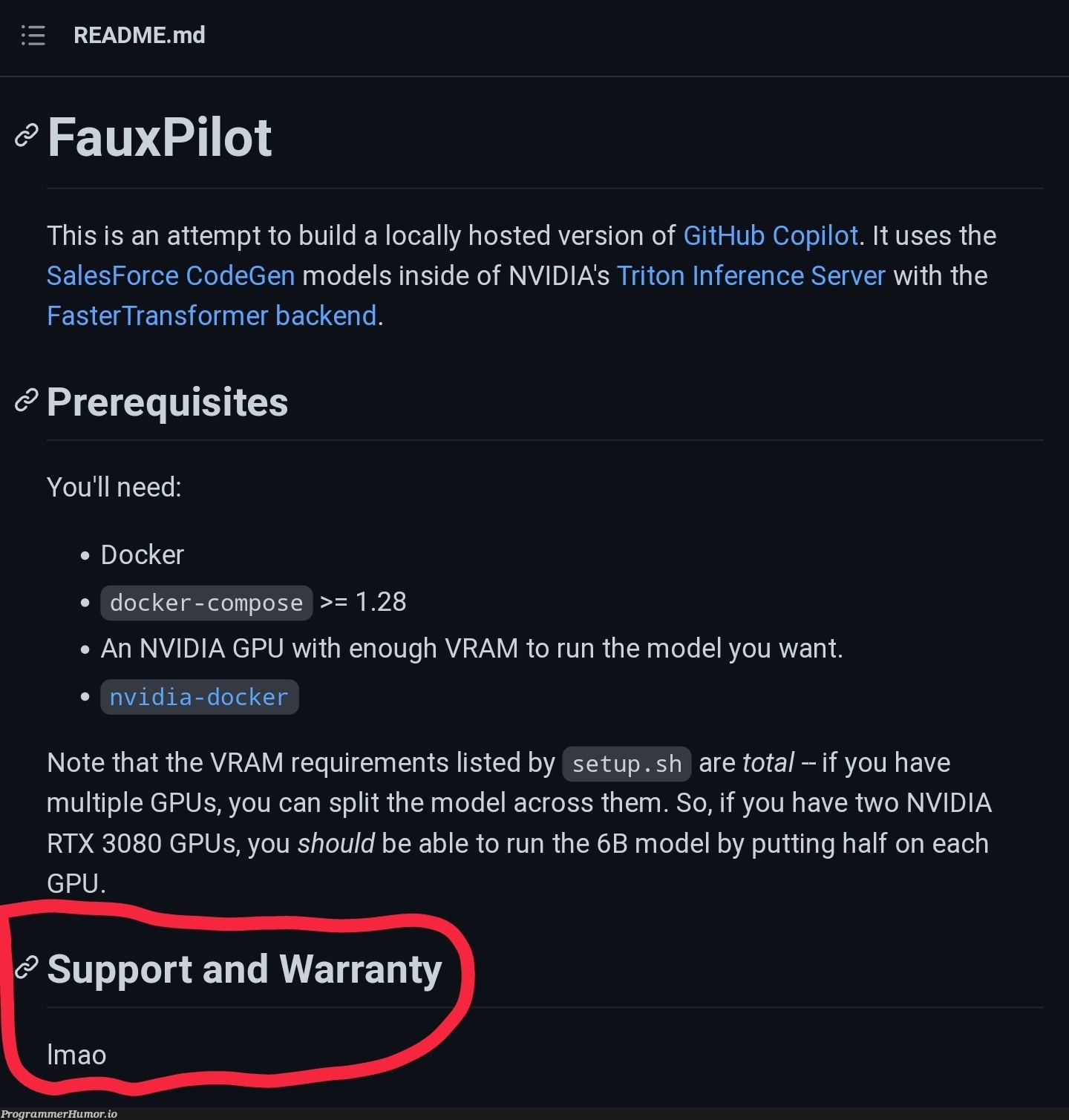
Content
README.md FauxPilot This is an attempt to build a locally hosted version of GitHub Copilot. It uses the SalesForce CodeGen models inside of NVIDIA's Triton Inference Server with the FasterTransformer backend. Prerequisites You'll need: Docker docker -compose 1.28 An NVIDIA GPU with enough VRAM to run the model you want. nvidia-docker Note that the VRAM requirements listed by setup. sh are total - if you have multiple GPUs, you can split the model across them. So, if you have two NVIDIA RTX 3080 GPUs, you should be able to run the 6B model by putting half on each GPU Support and Warranty Imao