AI
AI
 AWS
AWS
 Agile
Agile
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Azure
Azure
 Bash
Bash
 C++
C++

HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
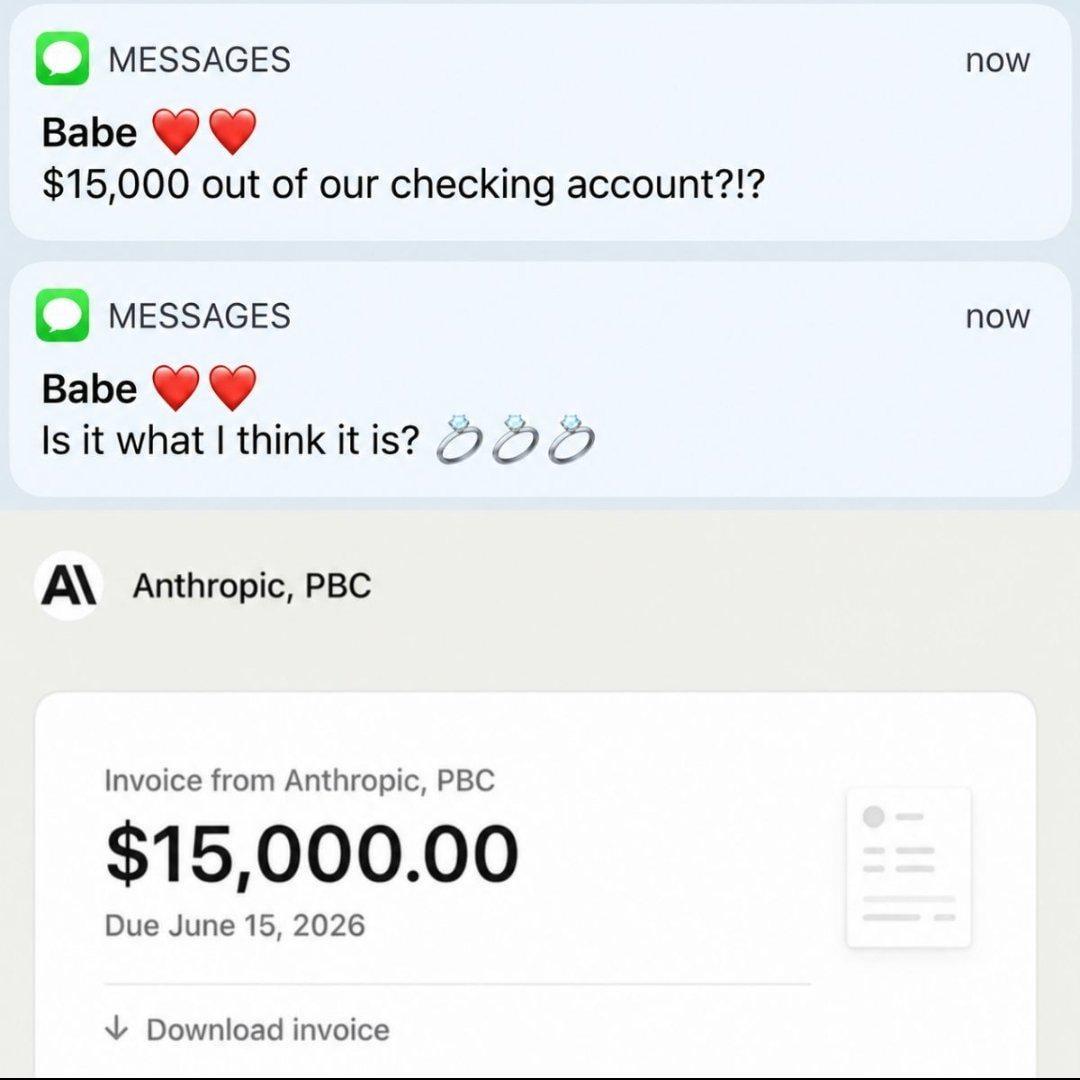
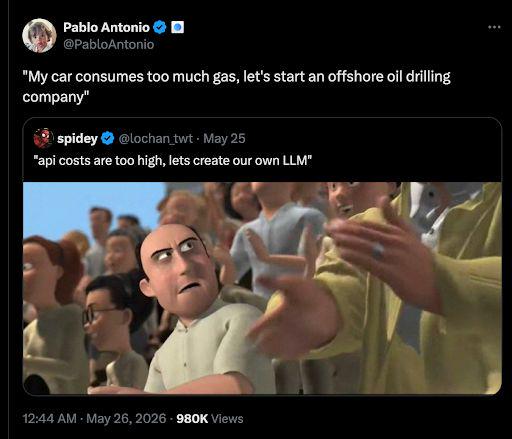
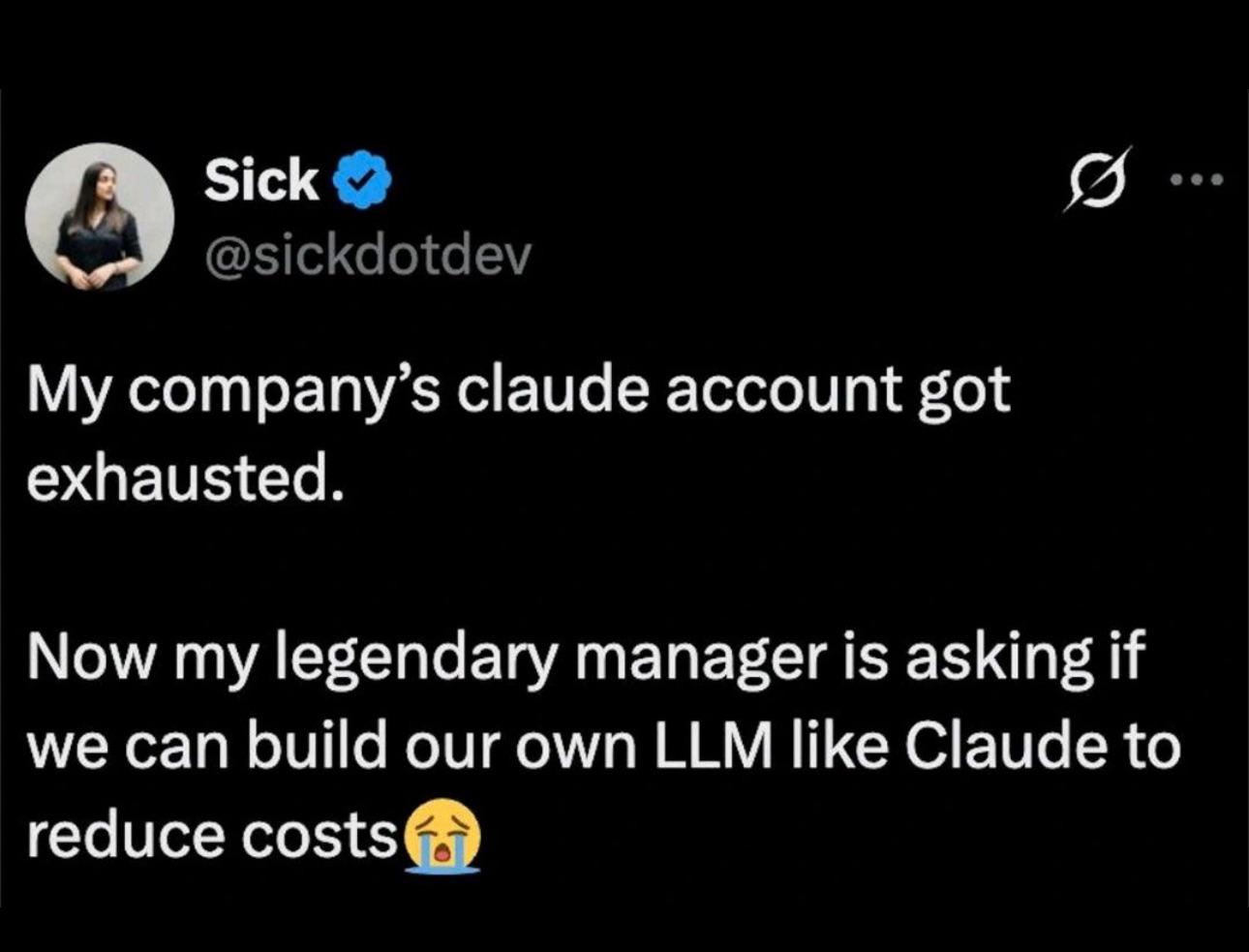
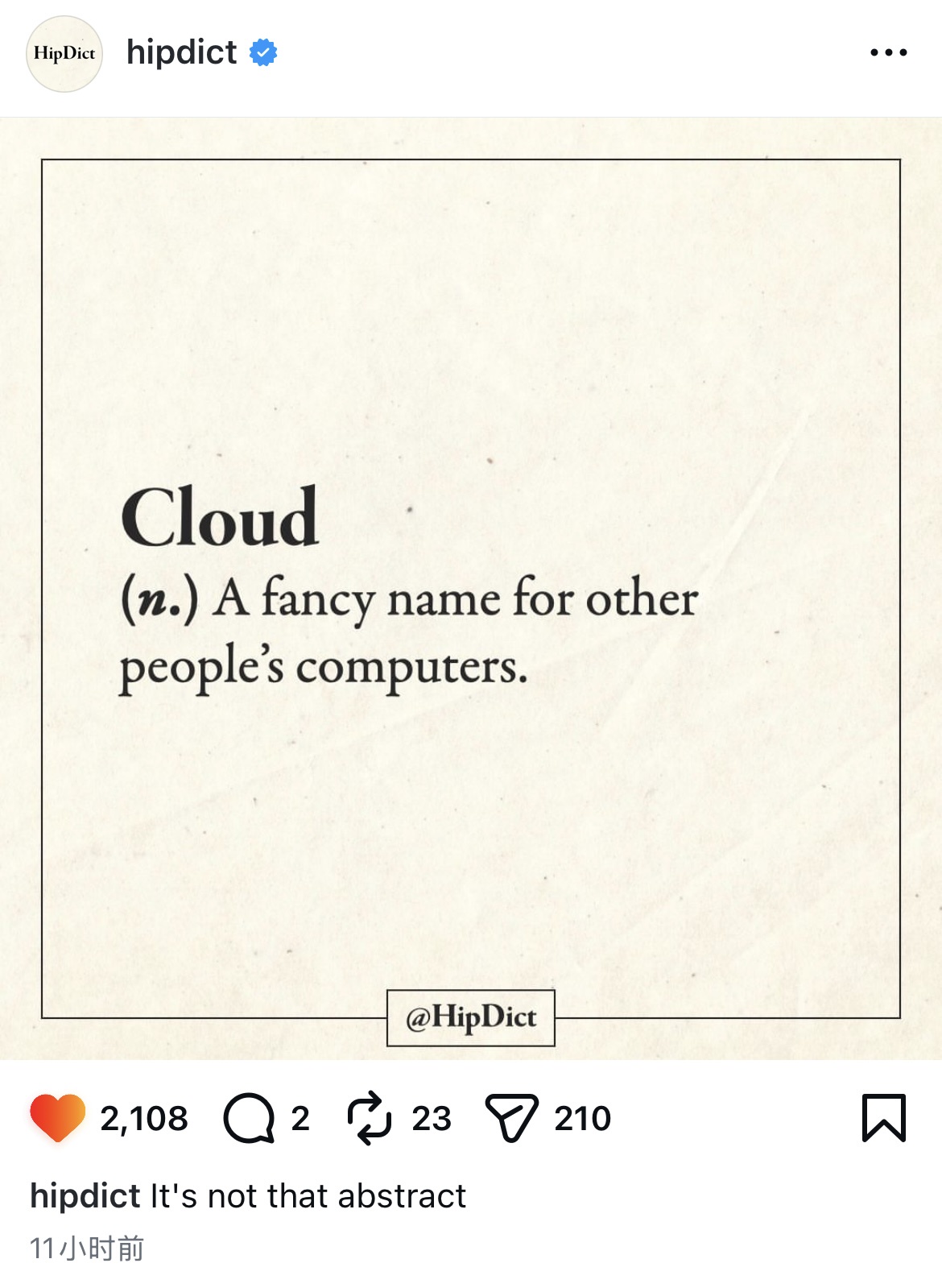
Cloud Memes
Cloud computing: or as I like to call it, 'someone else's computer that costs more than your car payment.' These memes celebrate the modern miracle of having no idea where your code actually runs. We've all been there – the shock of your first AWS bill, the Kubernetes config that's longer than your actual application code, and the special horror of realizing your production environment has been running on free tier resources for two years. Cloud promises simplicity but delivers YAML files that look like someone fell asleep on the keyboard. If you've ever deployed to the wrong region or spent hours configuring IAM permissions just to upload a single file, these memes will have you nodding through the pain.