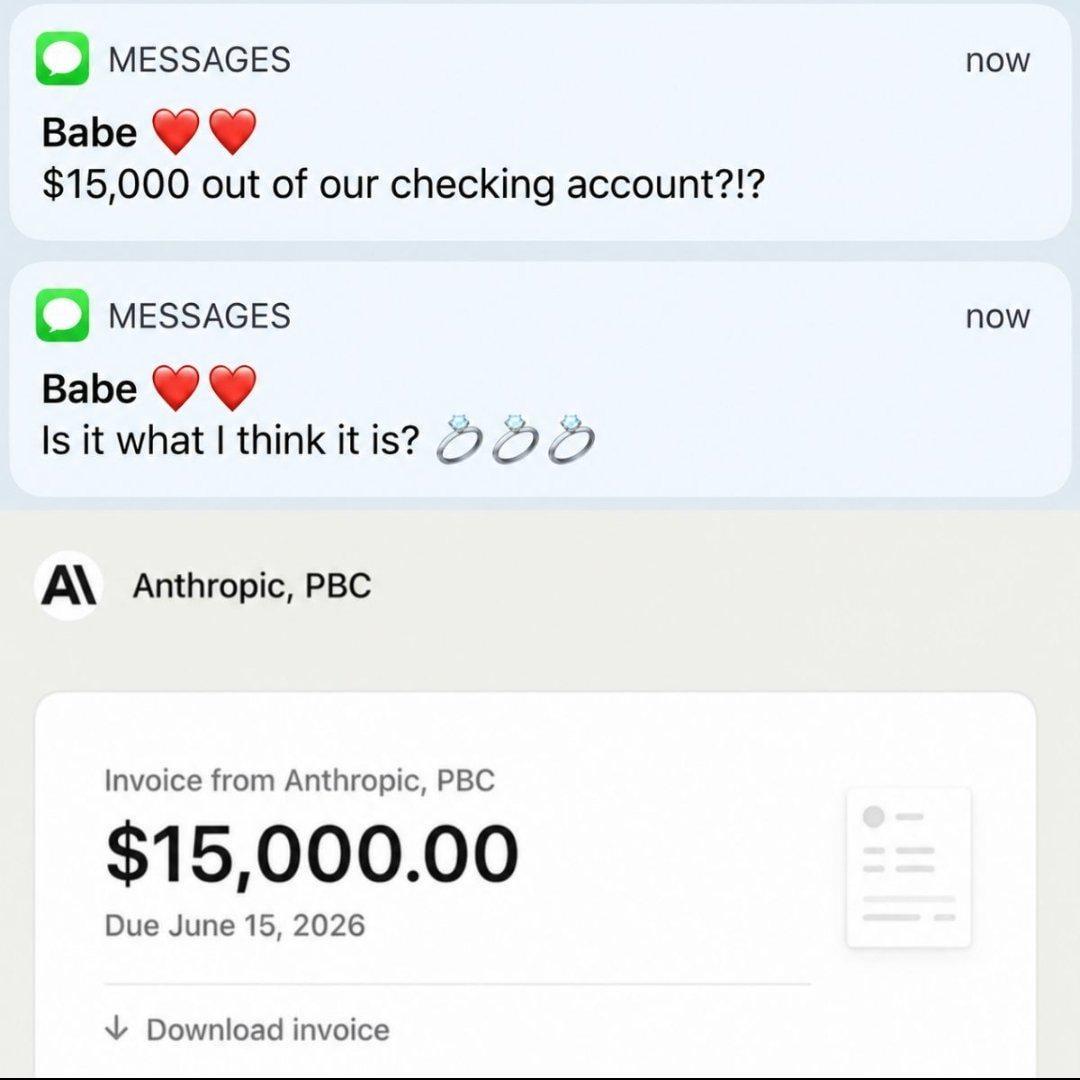
AI
AI
 AWS
AWS
 Agile
Agile
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Azure
Azure
 Bash
Bash
 C++
C++

HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
Devops Memes
DevOps: where developers and operations united to create a new job title that somehow does both jobs with half the resources. These memes are for anyone who's ever created a CI/CD pipeline more complex than the application it deploys, explained to management why automation takes time to implement, or received a 3 AM alert because a service is using 0.1% more memory than usual. From infrastructure as code to "it works on my machine" certificates, this collection celebrates the special chaos of making development and operations play nicely together.