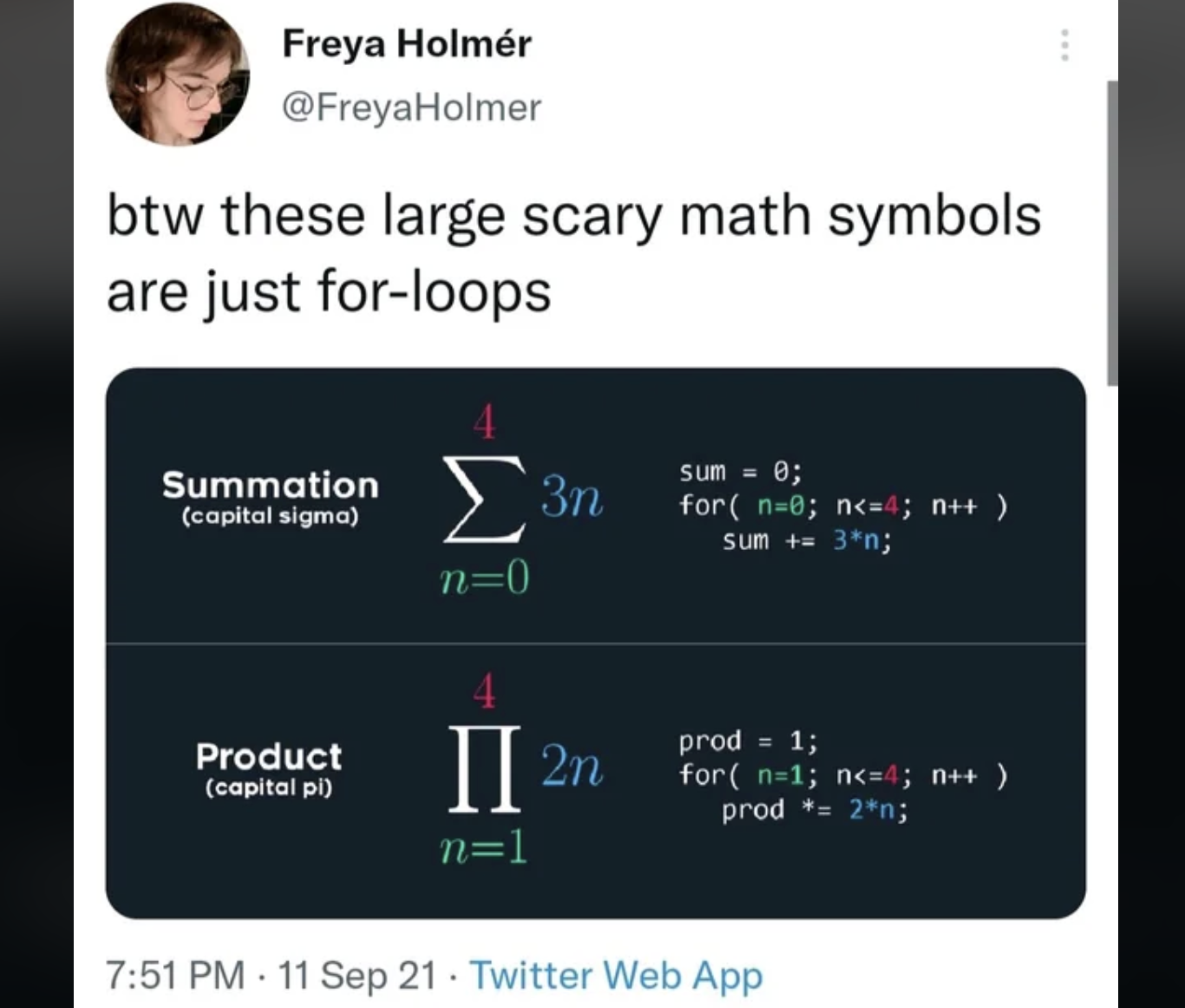
AI
AI
 AWS
AWS
 Agile
Agile
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Bash
Bash
 C++
C++
 Csharp
Csharp

O(n log n) is strutting around like it owns the place—buff doge, confident, the algorithm everyone wants on their team. Meanwhile O(n²) is just... there. Weak, pathetic, ashamed of its nested loops.
The truth? O(n log n) is peak performance for comparison-based sorting. Merge sort, quicksort (on average), heapsort—they're all flexing that sweet logarithmic divide-and-conquer magic. But O(n²)? That's your bubble sort at 3 AM because you forgot to optimize and the dataset just grew to 10,000 items. Good luck with that.
Every junior dev writes O(n²) code at some point. Nested loops feel so natural until your API times out and you're frantically Googling "why is my code slow." Then you learn about Big O, refactor with a HashMap, and suddenly you're the buff doge too.