 AI
AI
 AWS
AWS
 Agile
Agile
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Bash
Bash
 C++
C++
 Csharp
Csharp

HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
Reliability Memes
Posts tagged with Reliability
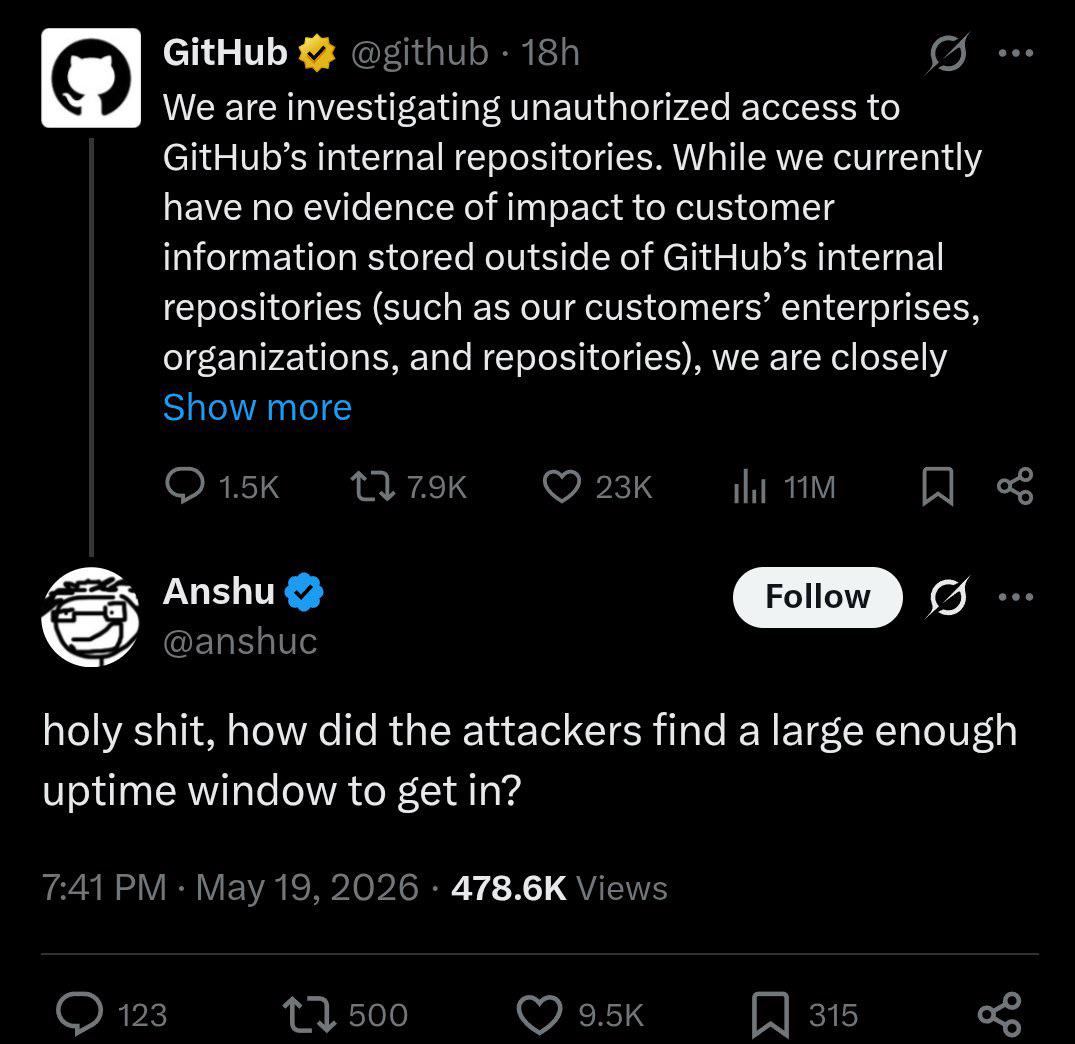

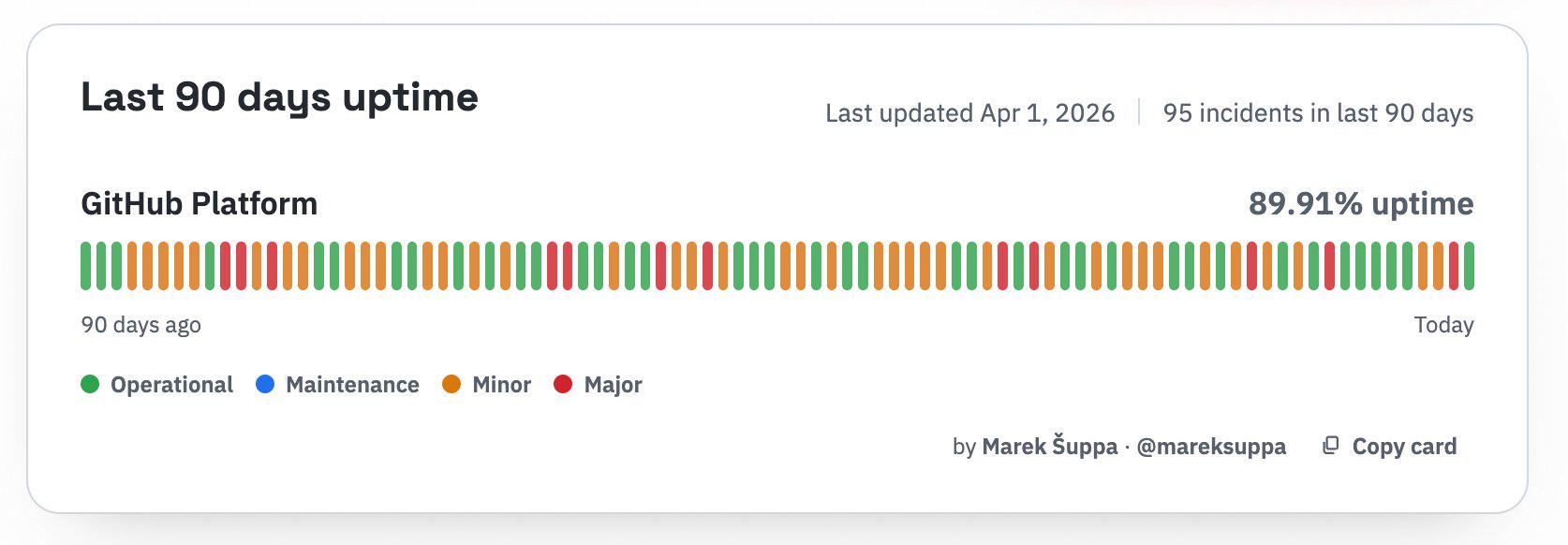
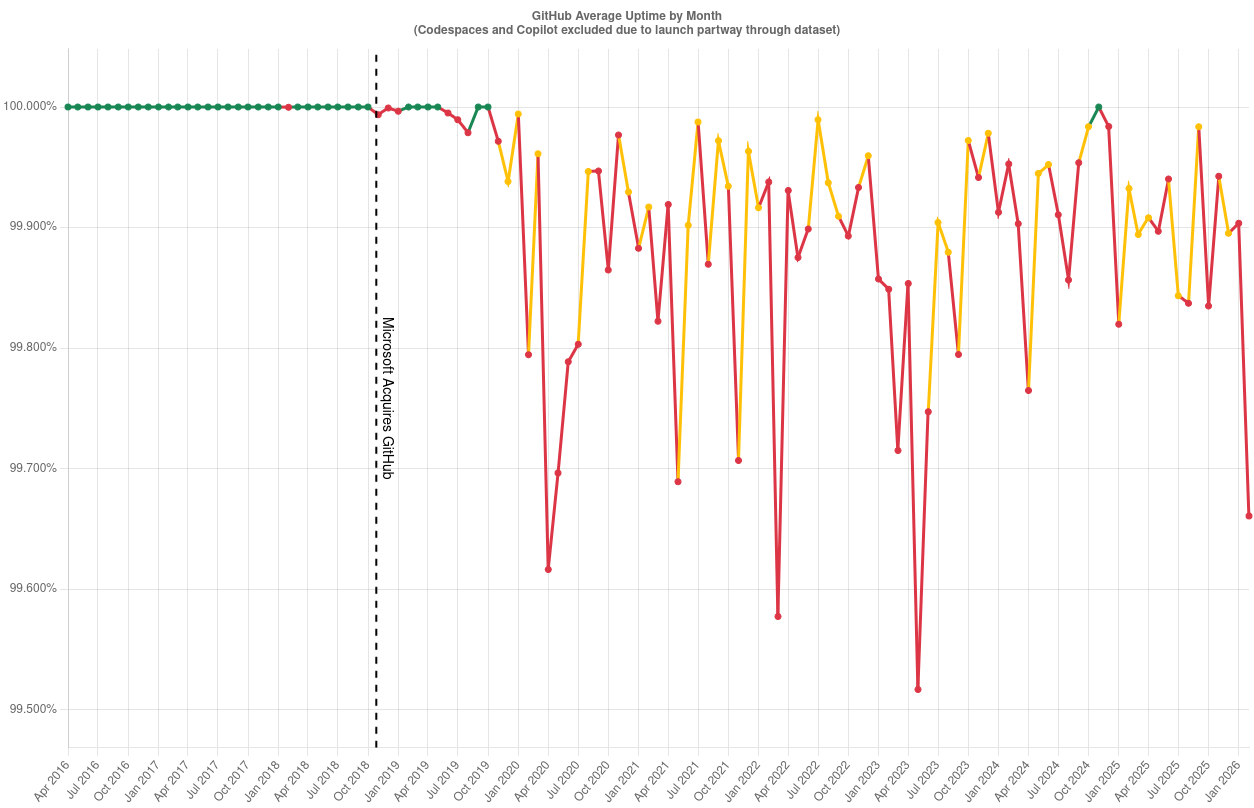







HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb
HTTP 418: I'm a teapot
The server identifies as a teapot now and is on a tea break, brb


