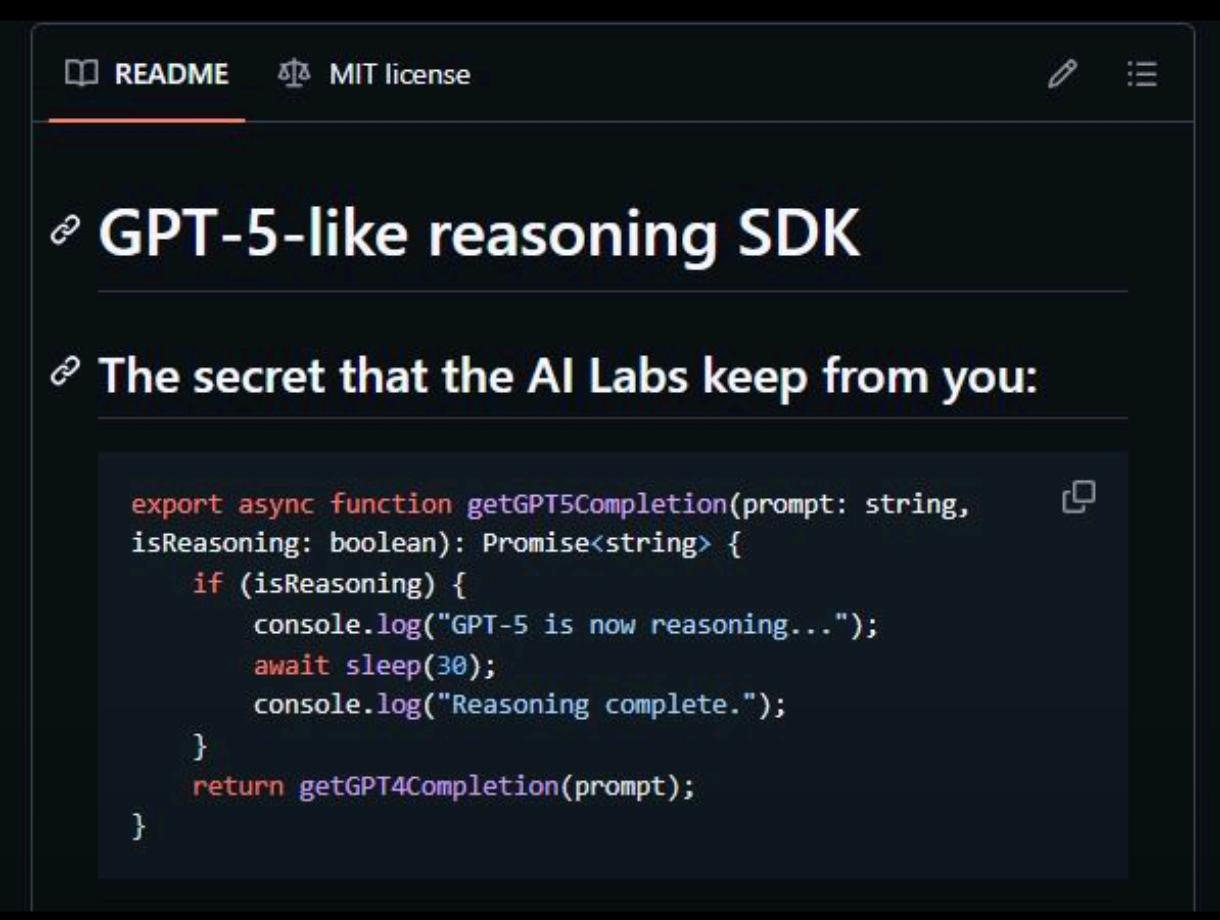
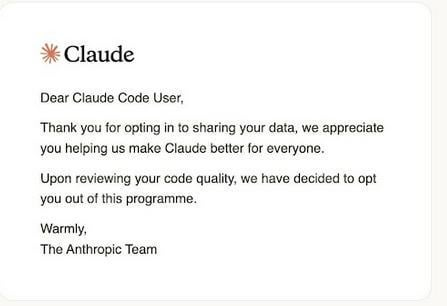
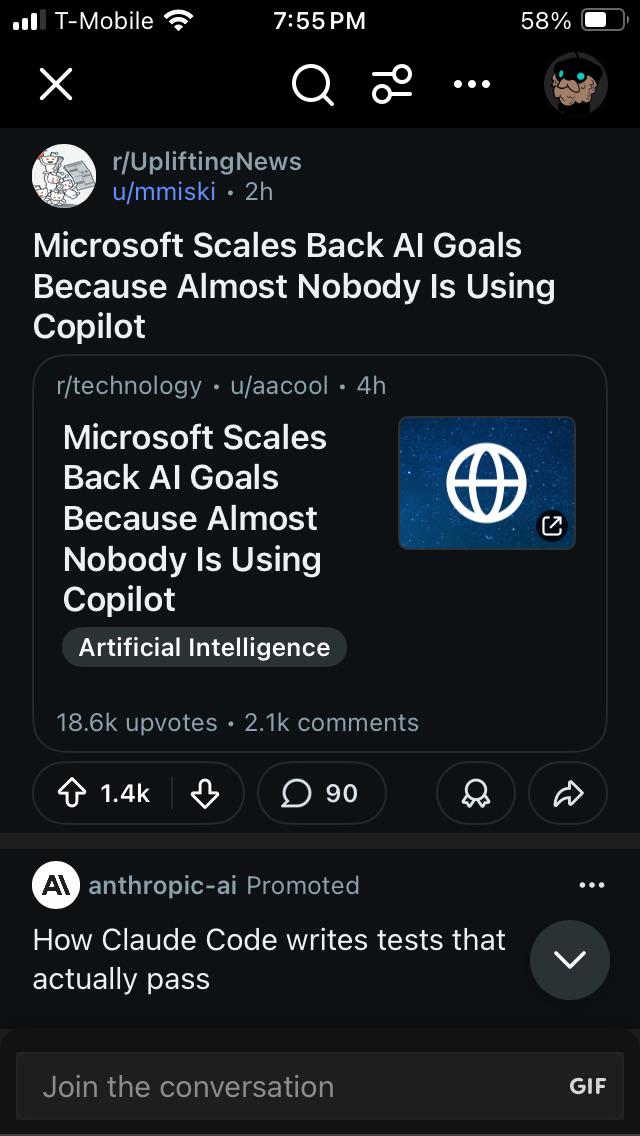
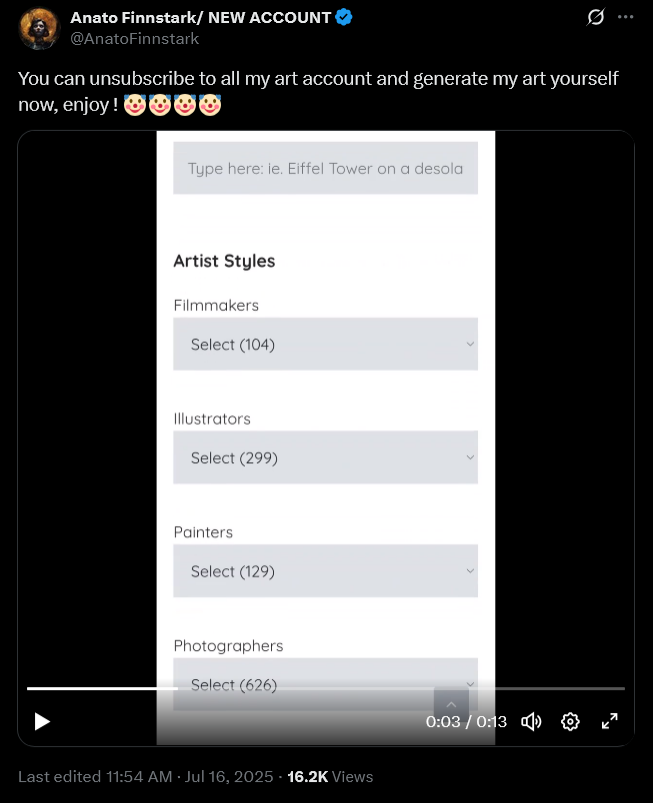
AI
AI
 AWS
AWS
 Agile
Agile
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Bash
Bash
 C++
C++
 Csharp
Csharp
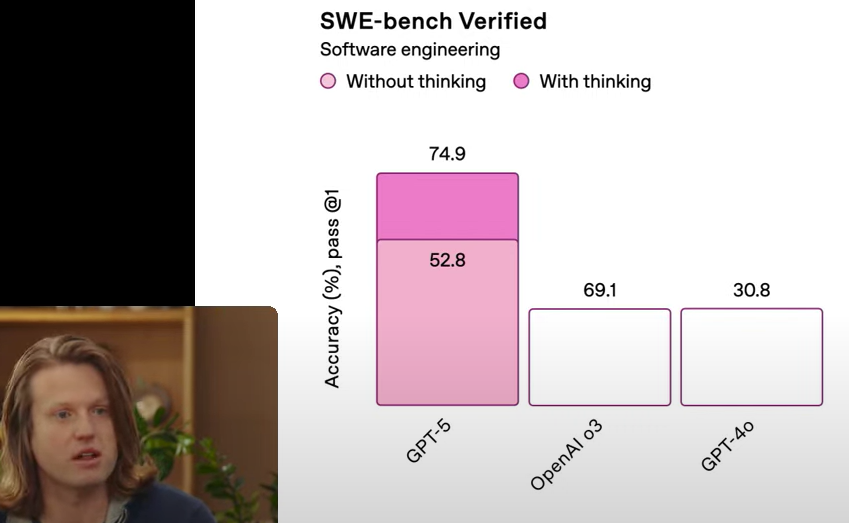
The chart hilariously reveals that GPT-5 scores a whopping 74.9% accuracy on software engineering benchmarks, but the pink bars tell the real story – 52.8% of that is achieved "without thinking" while only a tiny sliver comes from actual "thinking." Meanwhile, OpenAI's o3 and GPT-4o trail behind with 69.1% and 30.8% respectively, with apparently zero thinking involved. It's basically saying these AI models are just regurgitating patterns rather than performing actual reasoning. The perfect metaphor for when your code works but you have absolutely no idea why.
SWE-Bench Verified: Thinking Optional
ai-memes, machine-learning-memes, gpt-memes, benchmarks-memes, software-engineering-memes | ProgrammerHumor.io
More Like This