AI
AI
 AWS
AWS
 Agile
Agile
 Algorithms
Algorithms
 Android
Android
 Apple
Apple
 Bash
Bash
 C++
C++
 Csharp
Csharp
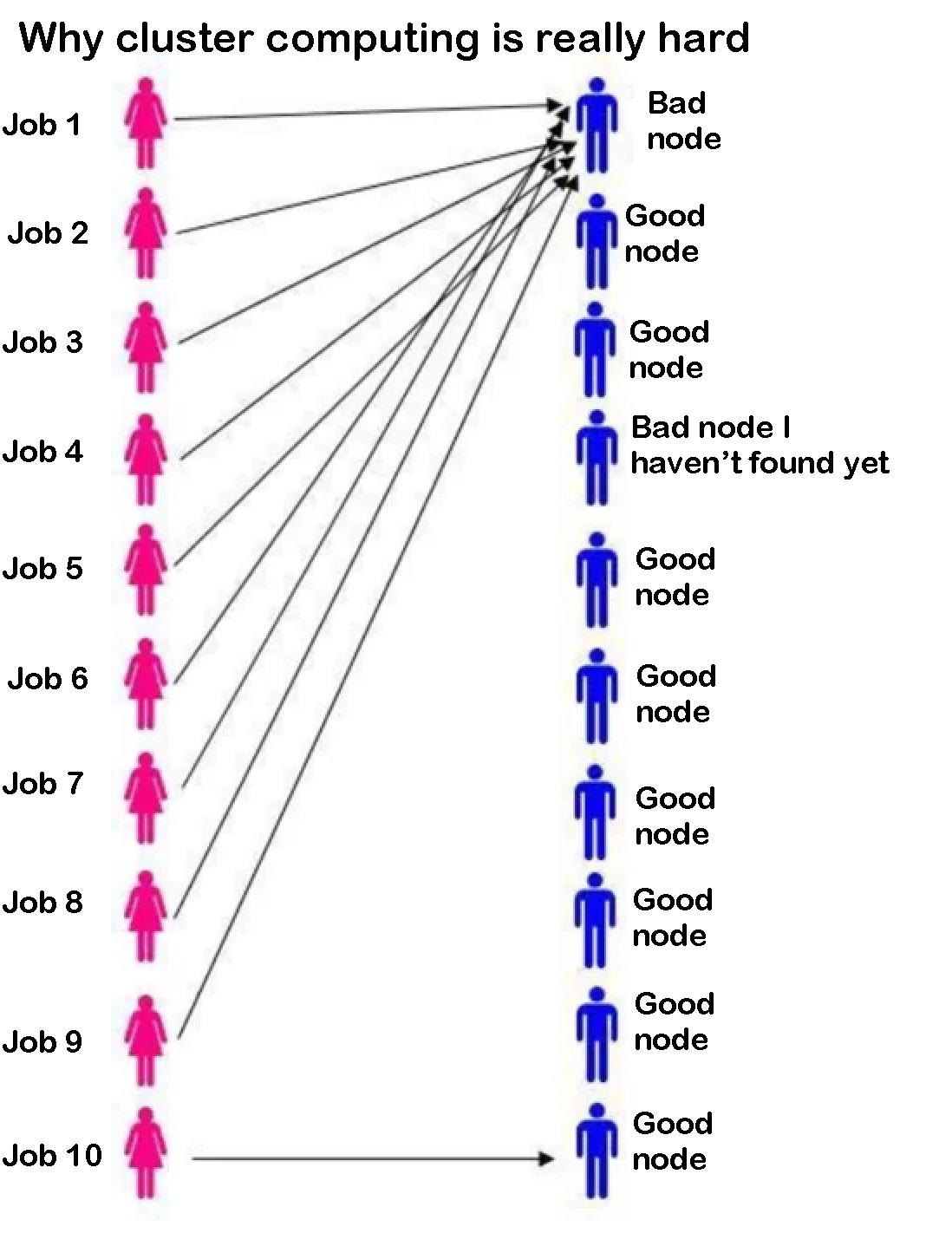
You've got 10 jobs to run, 9 perfectly good nodes ready to go, and somehow Job 4 decides to play Russian roulette with the one bad node that hasn't been discovered yet. Because of course it does. The scheduler's job assignment algorithm is basically throwing darts blindfolded at a dartboard where one dart is secretly a grenade.
The beauty of cluster computing: you have all these resources, but Murphy's Law ensures your critical job will land on the node with the faulty RAM stick that nobody's bothered to report yet. So you wait 6 hours for your job to fail, resubmit it, and pray to the HPC gods that this time it gets assigned to literally any other node. Rinse and repeat until your PhD defense date.
Fun fact: Slurm stands for "Simple Linux Utility for Resource Management," which is ironic because there's nothing simple about debugging why your job keeps failing on node-042.